
Making Apache Cassandra on IBM Cloud Kubernetes Production Ready — Part II
In a previous article, Part I started the discussion with how to run Cassandra on Kubernetes from the trenches of a production environment. The following items were the requirements we were working from
- Needs to be accessible inside and outside of the Kubernetes cluster. We have systems and applications that need to access Cassandra, some of which are not running in Kubernetes.
- Needs to support running in multiple Kubernetes clusters in different data centers and/or regions. We don’t have the option (yet) in IBM Cloud Kubernetes to extend a single Kubernetes cluster across regions. This also comes into the picture if you’re thinking of a hybrid cloud approach.
- Needs automated maintenance and backup procedures to run.
- Needs to support scaling out.
We covered most of these in Part I. For Part II, we’ll cover automated maintenance and backups.
Node Affinity
One of the benefits that Kubernetes gives us is the ability for it to schedule workloads across worker nodes. When a Kubernetes Pod goes down, or a worker node goes offline, Kubernetes will reschedule the Pod onto another worker node. While this is great for some applications, it’s not really necessary for Cassandra. Cassandra is already built to withstand individual nodes from going down, so have a Cassandra node start back up onto another worker node where another Cassandra node is running may not yield the best performance. Kubernetes gives us anti-affinity rules to allow us to keep Cassandra pods on different Kubernetes worker nodes. In order to achieve this, we tell Kubernetes not to schedule a Cassandra pod onto a worker node if there’s already a Cassandra pod running on that node.
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- cassandra
topologyKey: kubernetes.io/hostname
Maintenance
Cassandra doesn’t require very much attention on a regular basis. Running
nodetool repair is the main thing that needs to be done on a regular basis. Depending on your workload, this could be once a week, or daily, or anything in between. Running commands regularly is nothing new, and is usually solved today on non-container based environments using cron to schedule scripts. In the Kubernetes world, Jobs can run on a schedule and launch a Kubernetes pod to do some work. This is great for many situations, but I chose against using Kubernetes Jobs for a few reasons:- Some Cassandra maintenance tasks (i.e. backup) require access to the Cassandra file system. In order for me to have a single Job that has access to all Cassandra file systems, would require me to use an NFS File Storage to allow multiple Kubernetes pods to have read-write access to the same file system. For my setup, I was already using Block Storage.
- I wanted the maintenance tasks to scale with my Cassandra cluster. Meaning if I scale out from 3 to 6 nodes, I want my maintenance tasks to scale with it. In order for a Job to understand that we now have 6 nodes, would require me to write scripts that consume the Kubernetes API to figure out how many nodes are live. As well as modify the job to mount additional storage volumes (for the new nodes).
- Some Cassandra maintenance tasks require running
nodetool, which uses JMX to communicate with the Cassandra process. I didn’t want to open the JMX ports outside localhost and mess with securing and encrypting the traffic. This isn’t difficult, but would prefer to leave JMX to localhost only to reduce my attack surface.
Building Cron into the Cassandra Image
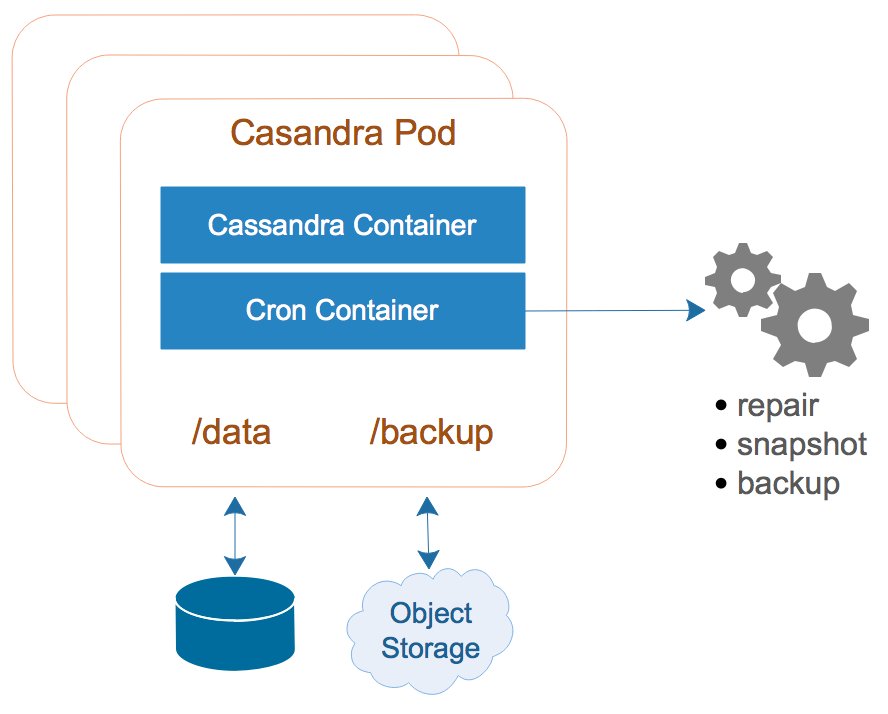
What I needed was a defined maintenance script that each Cassandra node was responsible for running at specific intervals. In this case, the script would be running with access to the same file system and environment that the target Cassandra node is running with, which simplifies the maintenance script and setup. It also allows me to scale out and scale down nodes because each node is responsible for running its maintenance script.
The general idea is to install cron on the Cassandra Docker image, along with a small shell script to launch it. I can then include a 2nd container in the Cassandra pod spec that mounts whatever crontab and maintenance script I want, and launches the shell script. Now I can define as many maintenance scripts as I want, and define the schedule for which the scripts run.
 The changes to the Dockerfile are to copy in the new
The changes to the Dockerfile are to copy in the new cron.sh script, install cron, and a few other things that may be needed by a cron script. The cron.sh script launches cron, and captures its PID so it can kill cron when SIGTERM is received. There’s a little known issue in the container world known as The PID 1 Issue where applications aren’t expecting to be the root parent process and don’t behave properly. There’s a great write up of that problem here. The cron.sh script handles this problem by trapping the SIGTERM and terminating the cron process.
The other thing
cron.sh does is define two environment variables CRON_STDOUT and CRON_STDERR. These environment variables can be used by any cron job to send output to the main container standard and error output streams. This is extremely useful to have available so you can see the output of the jobs and have the output sent to your central logging repository.
Here’s a sample set of ConfigMaps that can be used with this setup:
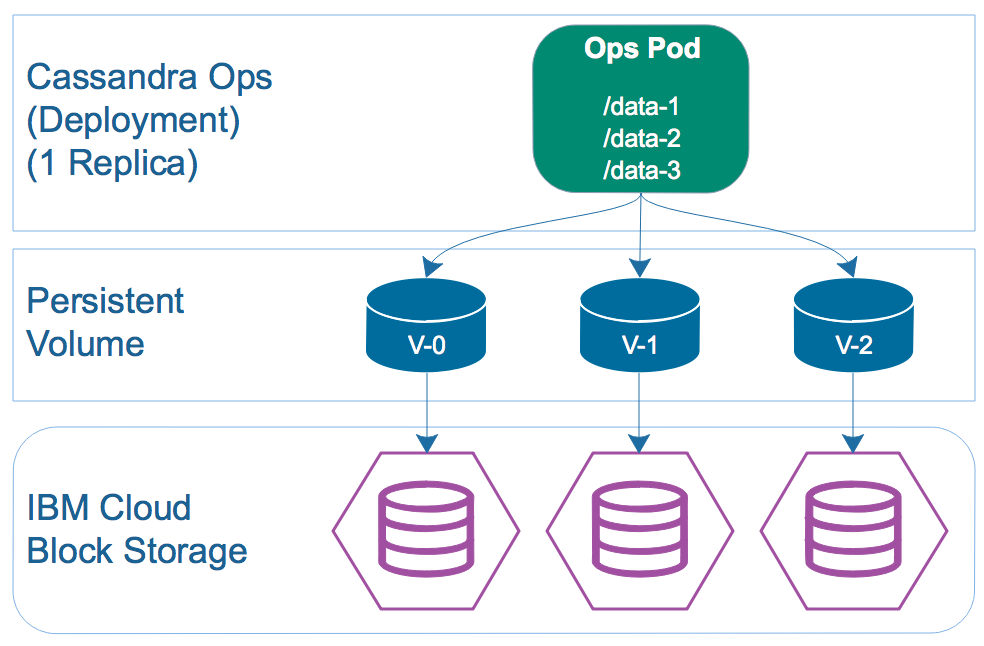 There are situations that may arise where you need to access the Cassandra storage volumes or backup volumes when Cassandra isn’t running. Perhaps Cassandra is failing to startup due to some corruption or other issue. Normally when this happens, you’d have to attach the storage and backup volumes to a new pod on the fly and start it up. Instead, I’ve created an Ops Deployment with all of the necessary info already for me and just set the number of replicas to zero. When I need to perform maintenance, I scale the Cassandra StatefulSet down to zero, and scale the Ops Deployment up to 1. I can then shell into the Ops pod and access all storage volumes.
There are situations that may arise where you need to access the Cassandra storage volumes or backup volumes when Cassandra isn’t running. Perhaps Cassandra is failing to startup due to some corruption or other issue. Normally when this happens, you’d have to attach the storage and backup volumes to a new pod on the fly and start it up. Instead, I’ve created an Ops Deployment with all of the necessary info already for me and just set the number of replicas to zero. When I need to perform maintenance, I scale the Cassandra StatefulSet down to zero, and scale the Ops Deployment up to 1. I can then shell into the Ops pod and access all storage volumes.
The first ConfigMap is the crontab file. It sources the same environment variables defined for the container so cron scripts will have access to the same variables. Line 10 demonstrates how the script output can be redirected to the standard output of the container. In this example, it’s redirecting standard out to the container out, and redirecting standard error to standard out so both regular and error output will be shown in the container output.
The only thing left is to mount these ConfigMaps into the appropriate place in the filesystem of the Cassandra image, and then write the actual maintenance script.
Updated Cassandra StatefulSet
Here is an updated StatefulSet definition and ConfigMap
You’ll notice in the StatefulSet definition on line 94 that I’m referring to a PersistentVolumeClaim cos-backup. This can be whatever storage volume you want to share across all nodes for backup purposes. For my purposes, I used IBM Cloud Object Storage, which can be created as a VolumeClaim. See here for details.
Looking closer at the maintenance script config map (line 28), you’ll see the script is performing a wait. The reason for this is that all Cassandra nodes can’t run a repair at the same time. If the cron schedule is the same for all nodes, and all nodes run the repair at the same time, the scripts will fail. In order to space out the repair operations, the script leverages the hostname of the node to obtain the node index within the StatefulSet (cassandra-0, cassandra-1, etc.). Using this index, the script wait a predefined number of minutes times the index. So cassandra-0 will wait 0 minutes; cassandra-1 will wait 10 minutes, and cassandra-2 will wait 20 minutes. The maintenance script also keeps a certain number of snapshots locally on the cassandra node’s storage volume to make it easier to restore a recent backup. The rest are stored on the backup volume, which in my example is backed by Cloud Object Storage.
Performing Maintenance When Cassandra Isn’t Running
There are situations that may arise where you need to access the Cassandra storage volumes or backup volumes when Cassandra isn’t running. Perhaps Cassandra is failing to startup due to some corruption or other issue. Normally when this happens, you’d have to attach the storage and backup volumes to a new pod on the fly and start it up. Instead, I’ve created an Ops Deployment with all of the necessary info already for me and just set the number of replicas to zero. When I need to perform maintenance, I scale the Cassandra StatefulSet down to zero, and scale the Ops Deployment up to 1. I can then shell into the Ops pod and access all storage volumes.Conclusion
As of this writing, I’ve had this setup deployed in a Production and Staging environment for 8 months with 5 keyspaces. The Production environment is deployed in 3 regions while the Staging environment is deployed across 2. Our Cassandra workloads are very read heavy and light on writes and have had zero issues thus far (fingers crossed). For monitoring, we use a beta feature of New Relic that allows us to use the Cassandra New Relic host integration in Kubernetes. It works very well and allows us to monitor performance and alert when response times get slow or nodes are going down. We also use LogDNA to monitor log files and send alerts when errors show up in the logs. All of this has resulted in a very easy to maintenance environment with the low costs and ease of deployments that Kubernetes gives.
Subscribe to:
Post Comments (Atom)










No comments:
Post a Comment